

Meet Headroom, the Open Source Project Built to Cut AI Token Spend
Headroom is an open source compression layer for AI agents. Learn how it works, where it shines, and results from using it on my agents

I was browsing GitHub, looking for interesting open source projects, when one caught my eye.
I do not do that often, but I keep reminding myself to do it more. Open source is having a special moment, as coding agents are helping people build more repos than ever. Still, many of the best ideas are hiding in plain sight.
The project is called Headroom. At the time, it had around 2,000 GitHub stars and claimed to reduce token usage by 60% to 95% when using Claude Code and the rest of the coding-agent gang. That got my attention.
I’ve had good results managing token spend by routing tasks to the right model, mostly Sonnet, some Opus, and just a tiny bit of Haiku. I’ve also been avoiding API usage like it’s radioactive. But for multi-agent systems running all day, or engineering teams shipping lots of code with AI, token spend becomes a much bigger problem.1 2
So today, I’ll share my experience with Headroom, and how you can use it to reduce token usage in both personal setups and more complex agentic systems.
What you’ll learn:
What Headroom is and who built it
How Headroom works
How I used it on Applied’s agents and development workflow
Why my token savings were closer to 10%
Where Headroom can reach 60% to 95% savings
How to set it up locally
Whether model providers could build this in
What is Headroom?
Headroom is an open source project created by Tejas Chopra, a Netflix engineer who works on storage and transfer systems for the platform’s huge content library.
The first commit happened in January, and the project stayed fairly quiet for the first few months. Then it started gaining real traction. By the time of writing, Headroom is sitting at around 30,000 GitHub stars, after jumping from roughly 3,000 in just one week.
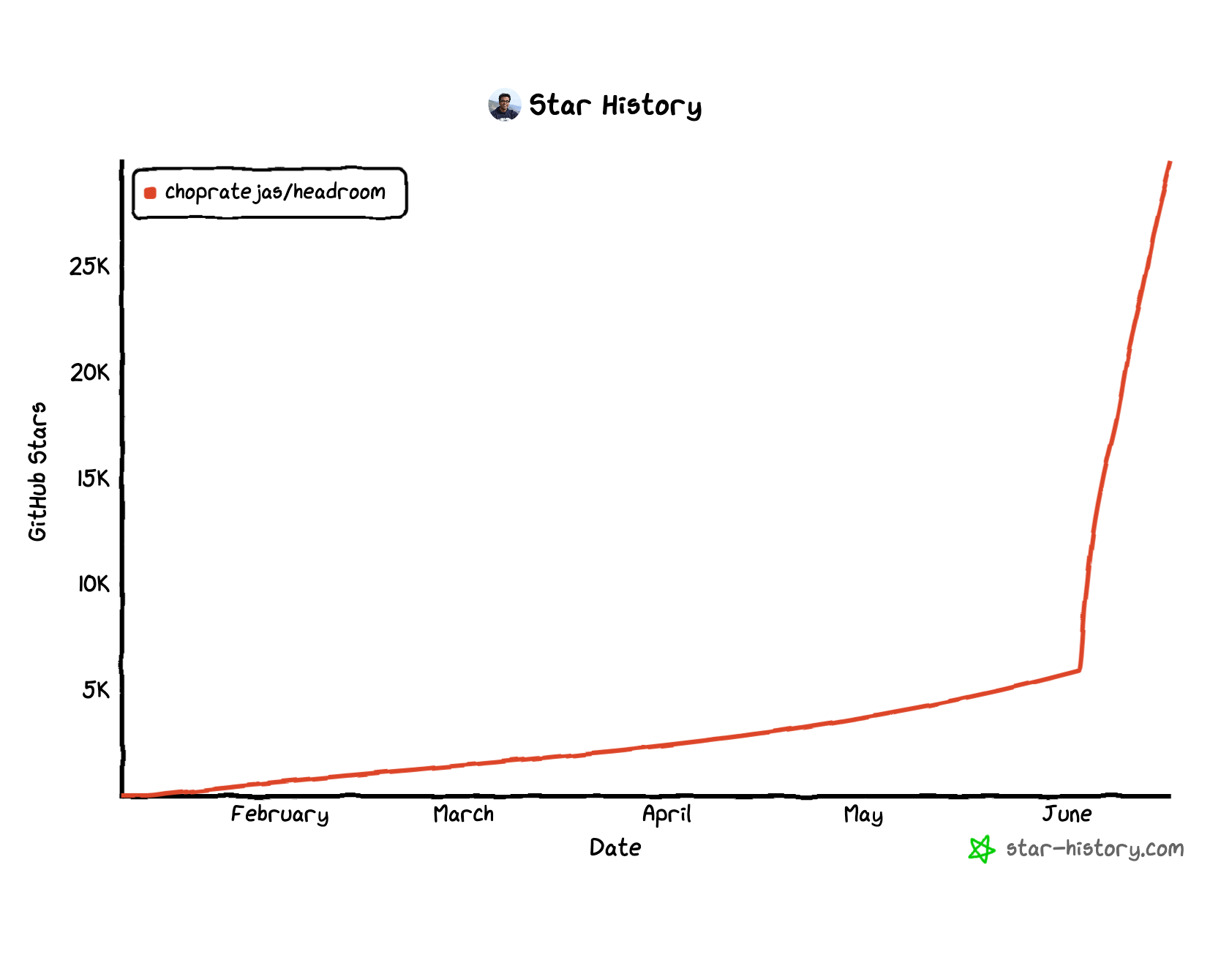
✅ GitHub Stars: are a way to “like” or “bookmark” a GitHub repo. They do not necessarily translate to usage. They are closer to a popularity signal, kind of like Instagram likes.
How does Headroom Work?
The Basic Architecture
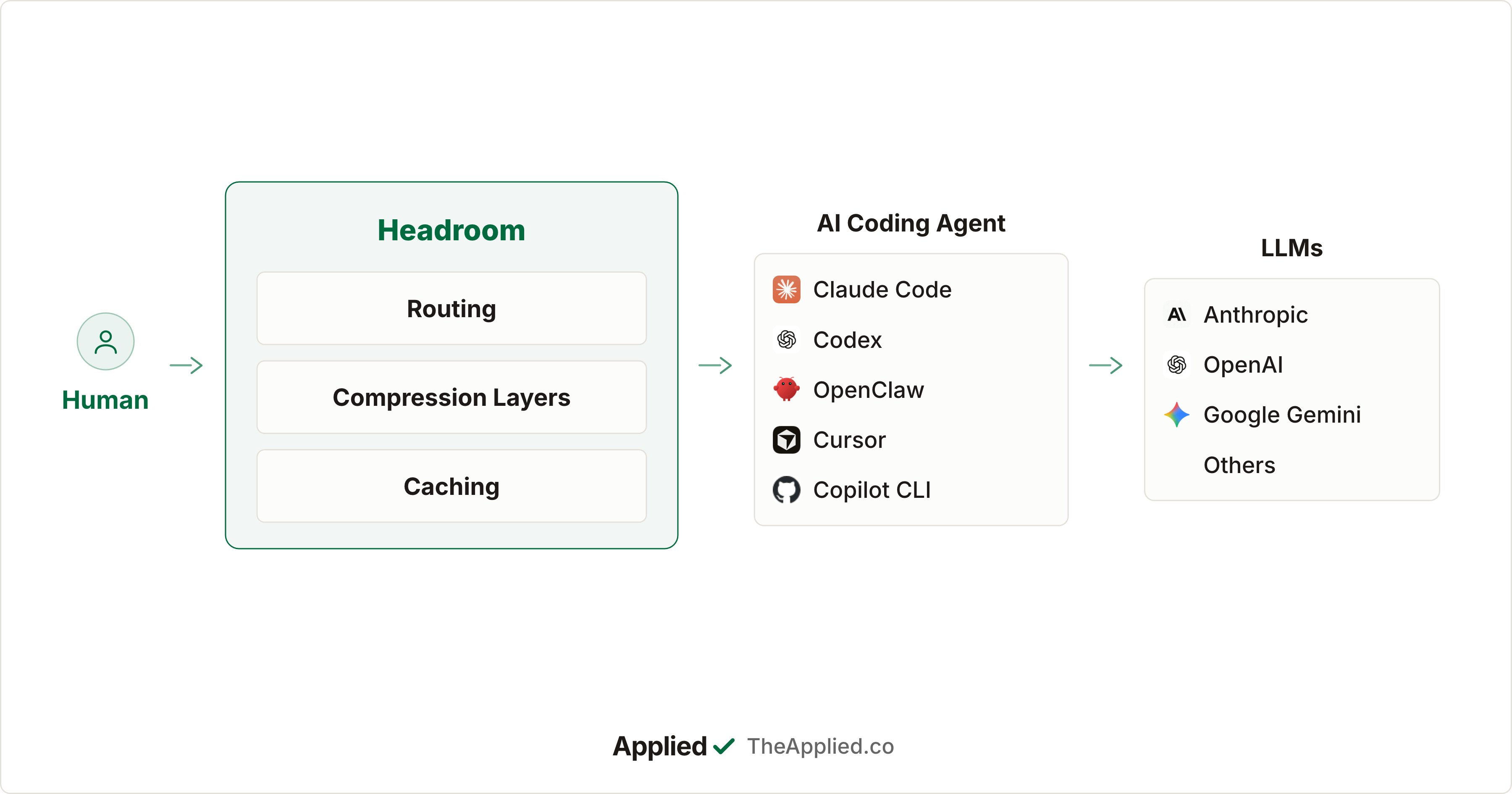
Headroom works like a compression layer between your AI agent and the LLM provider.
Before anything reaches the model, Headroom compresses the messy stuff: tool outputs, logs, RAG results, files, and conversation history. Then it sends a smaller prompt. The content stays local. Only compression and reduction stats are shared.
The pipeline has three main parts: routing, compression, and caching.
Routing
ContentRouter is the first stop for any incoming content. It detects the content type, such as JSON, code, prose, or logs, and sends it to the right compressor.
This is what makes Headroom content-aware, instead of just another generic summarizer.
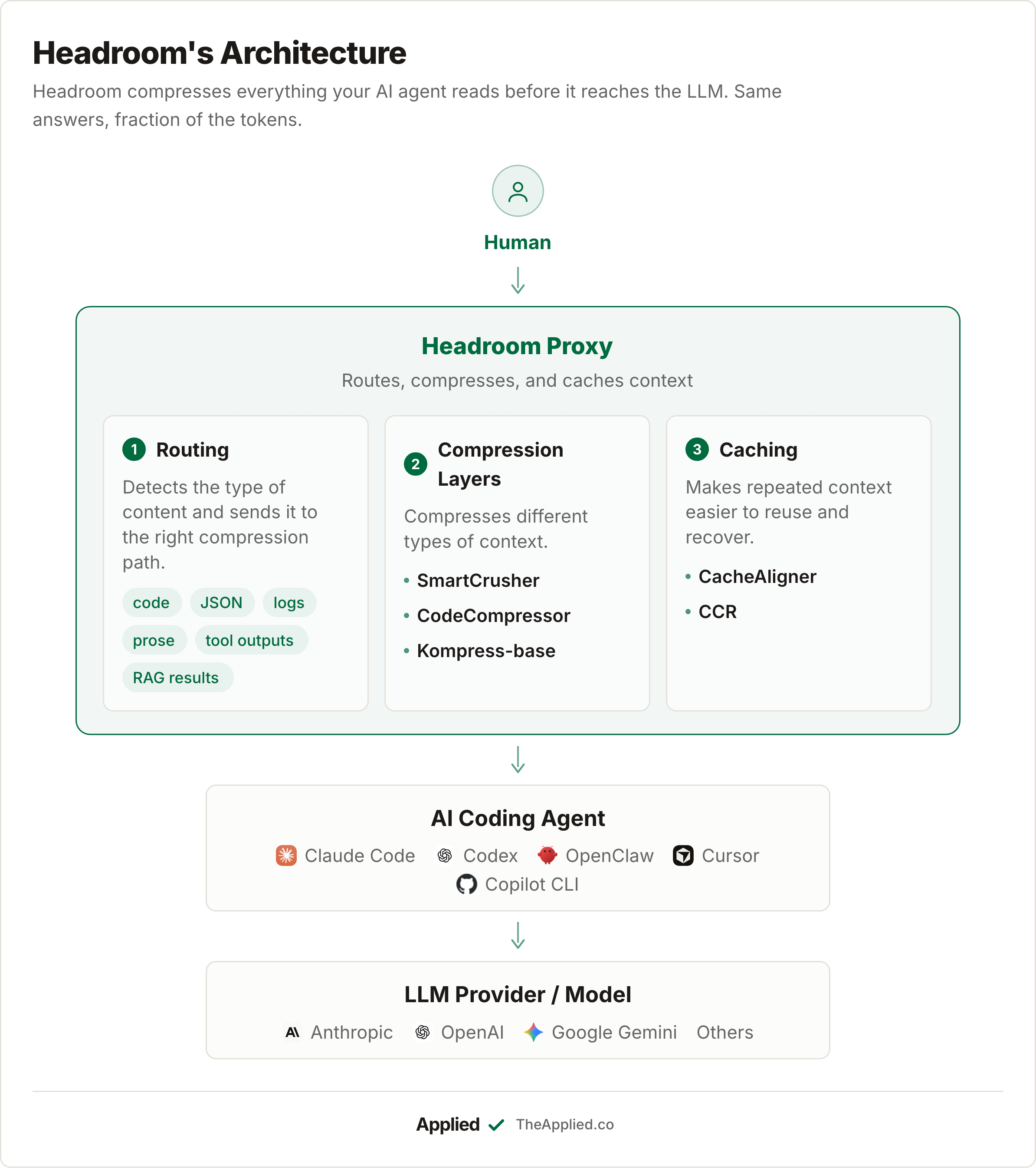
Compression Layers
SmartCrusher handles structured data: JSON arrays, nested objects, and tool outputs. It looks for repeated patterns and collapses them, achieving 70% to 90% reduction on typical tool call results.
CodeCompressor handles source code using AST, or Abstract Syntax Tree, parsing through tree-sitter. In plain English, it understands the structure of the code instead of treating it like normal text. It works across Python, JavaScript, Go, Rust, Java, and C++. It keeps the important parts, like imports, signatures, and types, while removing unnecessary code details.
Kompress-base is Headroom’s own open-weights model, hosted on Hugging Face and trained on agentic traces. It is used for prose, logs, search results, and diffs.
✅ Hugging Face: is a Machine Learning platform to share trained models and data sets. Think of it as GitHub for models.
Caching
CacheAligner helps repeated calls reuse provider-side caches from Anthropic, OpenAI, and others.
In plain English, it keeps message prefixes stable so the provider can recognize repeated context and avoid processing the same thing again. This can reduce latency and cost, even before compression helps.
CCR (Compress-Cache-Retrieve) makes compression reversible. Originals are stored locally, and the LLM can call a headroom_retrieve tool if it needs the full content again.
Nothing is permanently discarded.
Compression Patterns
Headroom’s savings change a lot depending on the task. Agent workflows create different kinds of context, and some are much easier to compress than others.

Code search: 92% reduction, 17,765 → 1,408 tokens
Search results over a codebase usually include a lot of repeated content: file headers, boilerplate, duplicated matches, and other low-value details. SmartCrusher and CodeCompressor can compress this aggressively because the structure is fairly predictable.
SRE incident debugging: 92% reduction, 65,694 → 5,118 tokens
Incident debugging usually pulls in logs, stack traces, and monitoring outputs. These often include repeated log lines, timestamps, and templated error messages, which compress extremely well.
GitHub issue triage: 73% reduction, 54,174 → 14,761 tokens
Issue threads are a mix of structured metadata, comments, code snippets, and messy human discussion. Compression still works well here, but it needs to be more careful because the natural-language parts often carry more unique context.
Codebase exploration: 47% reduction, 78,502 → 41,254 tokens
Exploring an unfamiliar codebase is harder to compress. The model receives many different files, languages, and pieces of logic. There is less repetition, so Headroom has less room to compress without risking useful context.
The pattern is clear: repetitive content, like logs and search results, gets the biggest savings. Varied content, like code exploration or issue discussions, needs more careful compression.
Using Headroom on Applied’s Research Agents
I took Headroom for a spin with my personal Claude Code setup, Applied’s 6-agent research system, and the Adoption Signals workflow.
Here is what happened.